

问题1:分类问题的交叉熵是什么?
分类问题的交叉熵(cross-entropy)是一种用来衡量分类模型输出与真实标签之间差异的指标。在二分类问题中,交叉熵可以表示为以下公式:
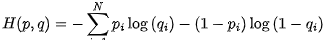
其中,p 表示真实标签,q 表示模型预测的标签,N 表示样本数量。该公式可以看作是一个基于概率分布的比较方式,即将真实标签看做一个概率分布,将模型预测的标签也看做一个概率分布,然后计算它们之间的交叉熵。
问题2:分类问题是否可以用MSE?
分类问题通常不能使用均方误差(MSE)作为损失函数,因为分类问题中的标签通常是离散的,而 MSE 适用于连续变量的回归问题。当使用 MSE 作为损失函数时,模型的输出可能会超过 1 或小于 0,这是因为 MSE 的计算方式不适用于概率值的范围。在分类问题中,常用的损失函数包括交叉熵、对数损失函数等。
问题3:推荐系统中,相比于余弦相似度,是否可以用欧几里得距离判断相似度?
在推荐系统中,通常使用余弦相似度来度量用户或物品之间的相似度。因为余弦相似度考虑的是向量之间的夹角,而不是向量的长度,因此它对于不同大小的向量比较稳健。而欧几里得距离则是考虑向量之间的长度,因此对于不同大小的向量比较敏感。在推荐系统中,通常物品或用户的特征向量长度不同,因此欧几里得距离不适用于推荐系统中的相似度度量。
问题4:过拟合怎么处理?
过拟合是指模型在训练集上表现良好,但在测试集上表现较差的现象。过拟合的原因通常是模型过于复杂,参数过多,导致模型在训练集上过度拟合。常见的处理方法包括以下几种:
- 增加数据量:通过增加训练数据来降低模型对于训练集的过度拟合。
- 简化模型:减少模型的参数量,简化模型的结构,降低模型的复杂度。
- 正则化:通过在损失函数中添加正则化项,限制模型参数的大小,从而避免模型过度拟合。常见的正则化方法包括 L1 正则化和 L2 正则化。
- 提前停止训练:通过监控模型在验证集上的表现,当模型在验证集上的表现不再提升时,提前停止训练,避免模型在训练集上过度拟合。
问题5:L1、L2正则化的效果、区别、原理?
L1 正则化和 L2 正则化都是正则化方法,目的是通过限制模型参数的大小,降低模型的复杂度,防止过拟合。L1 正则化会使一部分参数变为 0,从而实现特征选择的效果,适合处理稀疏数据。L2 正则化则会让所有参数都趋向于较小的值,但不会使参数为 0。
L1 正则化的损失函数可以表示为:
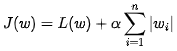
其中,L(w) 是模型在训练集上的损失函数,w_i 是模型的第 i 个参数,\alpha 是正则化强度的超参数。
L2 正则化的损失函数可以表示为:
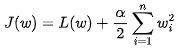
其中,L(w)、w_i 和 alpha 的含义与 L1 正则化相同。
问题6:Dropout的原理、在训练和测试时的区别?
Dropout 是一种常用的正则化方法,其原理是在每次迭代中随机将一部分神经元的输出置为 0,从而减少神经元之间的共适应性,防止过拟合。
在训练时,Dropout 会随机将一定比例的神经元的输出置为 0,从而产生多个不同的子网络,每个子网络都只学习了部分信息,强制使网络更加鲁棒。在测试时,为了保持网络的稳定性,Dropout 通常被关闭,而是使用训练时每个子网络的加权平均作为最终的预测结果。
问题7:SGD、Adam、动量优化的SGD?
SGD(Stochastic Gradient Descent)是一种基本的梯度下降算法,它使用单个样本的梯度来更新模型参数,从而实现对损失函数的最小化。SGD 的缺点是可能会陷入局部最优解,并且收敛速度较慢。
动量优化的 SGD(Momentum SGD)是在 SGD 的基础上引入了动量的一种优化算法。动量可以看作是给梯度增加一个惯性项,使得在更新参数时,当前的梯度不仅考虑当前时刻的梯度,还会考虑之前的梯度信息,从而使得更新方向更加平稳,收敛速度更快。
Adam 是一种基于梯度的优化算法,结合了 RMSProp 和动量优化的思想。Adam 通过维护一个梯度的指数加权移动平均和梯度平方的指数加权移动平均来自适应地调整每个参数的学习率,从而实现快速的收敛。
问题8:Adam和动量优化的SGD效率上的区别?
相对于动量优化的 SGD,Adam 有以下几个优点:
- 自适应性:Adam 能够自适应地调整每个参数的学习率,从而使得模型在不同的参数空间下能够更加快速地收敛。
- 速度快:Adam 在训练过程中能够快速地找到最优解,因此通常能够在较少的迭代次数内达到更好的性能。
- 可靠性高:Adam 对超参数的选择不太敏感,因此更容易调整到最优参数。
但是,Adam 也有一些缺点。例如,Adam 对于噪声较大的梯度可能会表现不稳定,并且在处理非凸问题时可能会出现性能下降的情况。
问题9:推荐系统中,如何进行负采样?
在推荐系统中,负采样是一种重要的技术,用于构造负样本,以便训练推荐模型。一般而言,推荐系统的正样本很少,负样本很多,因此负采样可以大大加快训练的速度和提高模型的准确率。
负采样的过程通常可以分为以下几个步骤:
- 计算每个物品的权重:对于每个物品,根据其流行度或其他相关因素计算其权重,权重越高的物品越容易被采样为负样本。
- 根据权重进行采样:根据每个物品的权重进行随机采样,以得到一定数量的负样本。采样的过程通常可以使用一些概率分布,如指数分布或幂律分布等。
- 去除已有的正样本:从采样得到的负样本中去除已有的正样本,以确保训练集中不会出现重复样本。
- 控制负采样比例:为了保持正负样本之间的平衡,通常需要控制负采样的比例,即每个正样本对应的负样本数量。对于多个用户和物品的推荐问题,可以通过对每个用户和物品分别进行采样来生成一定数量的正负样本对。
留言